*XML is a self describing data format which can be used in the communication between the client and server.
*An element name must begin with a letter/underscore. It must never start with “xml”(reserved for xml–>1.0spec).
*CDATA section allows you to mark a section of text, as literal so that it will not be parsed for tags & symbols. Those will be considered as strings.
*xmlns = “some uri” –> which confirms to the URI specification RFC 2396. defined by IETF.
*URI can take many forms the most common one is URL.
*The URI used for the xml namespace should be unique to that markup language and doesn’t have to point to a actual resource/document.
*In XML speak a prefix combined with an element name is called a “Qname”.
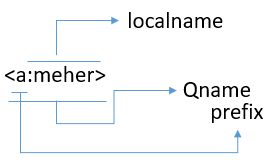
*XML parsers & other tools use xml namespace to process, sort and search xml elements in a document according to their “Qnames”.
*DTD fails to address data typing(weak typing). [empty, any, element content, mixed content].
*Complex types describe how elements are organized and nested.
*Simple types are the primitive data types contained by elements and attributes.
*XML schema spec uses 44 simple types called built in types

*Xerces -J, supports schema validation while ‘crimson’ not support.
*Jdom, dom4j and Xom are non standard xml java api.
*All simple and complex types are ultimately derived from “anytype”.
*When an element declares that it is of a particular type, it must specify both the name space & the name of that type exactly as the type declares them.
*default value for ‘minOccurs’ & ‘maxOccurs’ is “1”.
*’maxOccurs’ can be unbounded.
*’default’ attribute is used only when “use” attribute is optional.

